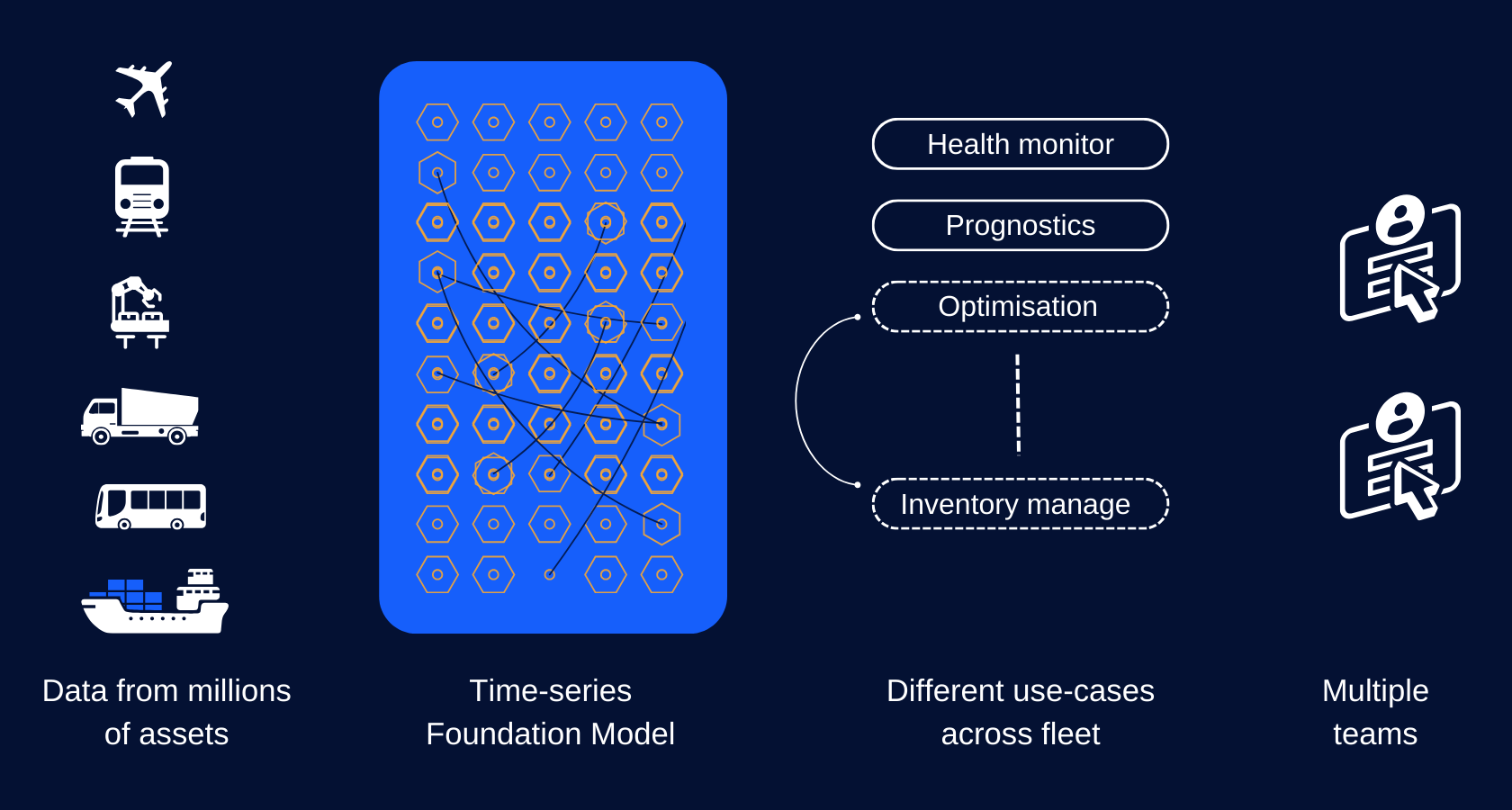



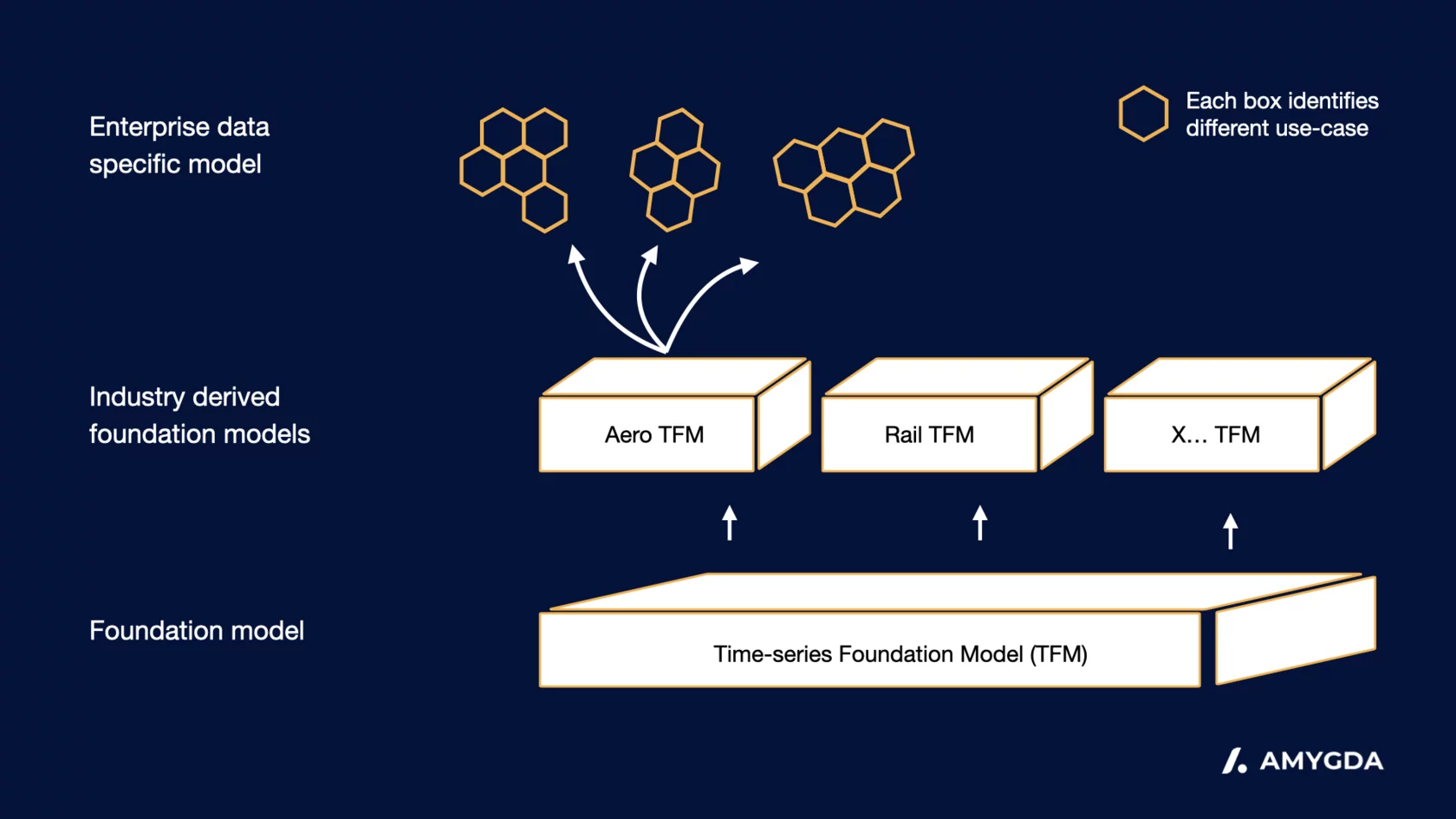
"We are at pivotal moment when cross industry developments in AI can finally be effectively leveraged in the very traditional transport domains where the application has been slow, painful and impractical. It requires a whole new way of thinking and Amygda's reusable, flexible and explainable AI changes how we deliver the promise of AI to the transport industry. The shift has already begun and Amygda's leading the way!"

Shaheryar Khan
Co-Founder and AI Lead
