
DB Regio is a subsidiary of Deutsche Bahn which operates regional and commuter train and bus services in Germany. DB Regio runs 21,000 train services every day across Germany.
The hardest ones to get right? First trains of the morning.
These trains come from overnight maintenance. They’ve been sitting idle. Maybe maintenance finished. Maybe it didn’t. Maybe there’s a technical issue no one spotted yet.
Control centre dispatchers have no way to know until the train tries to start.
By then, passengers are waiting on platforms.
DB Regio was already collecting a lot of maintenance logs
Over 1,600 different fault codes recorded across multiple systems. More than 250 million data files scattered through damage reports, vehicle allocation systems, and operational logs.
All that data. But near zero visibility into which first trains might fail. Manually analysing so much data whilst making sure trains run on time hour by hour is a difficult task.
Dispatchers could only react after problems surfaced. About 20% of passenger communications came too late – after delays already started.
What Changed with Amygda’s Risk Scores
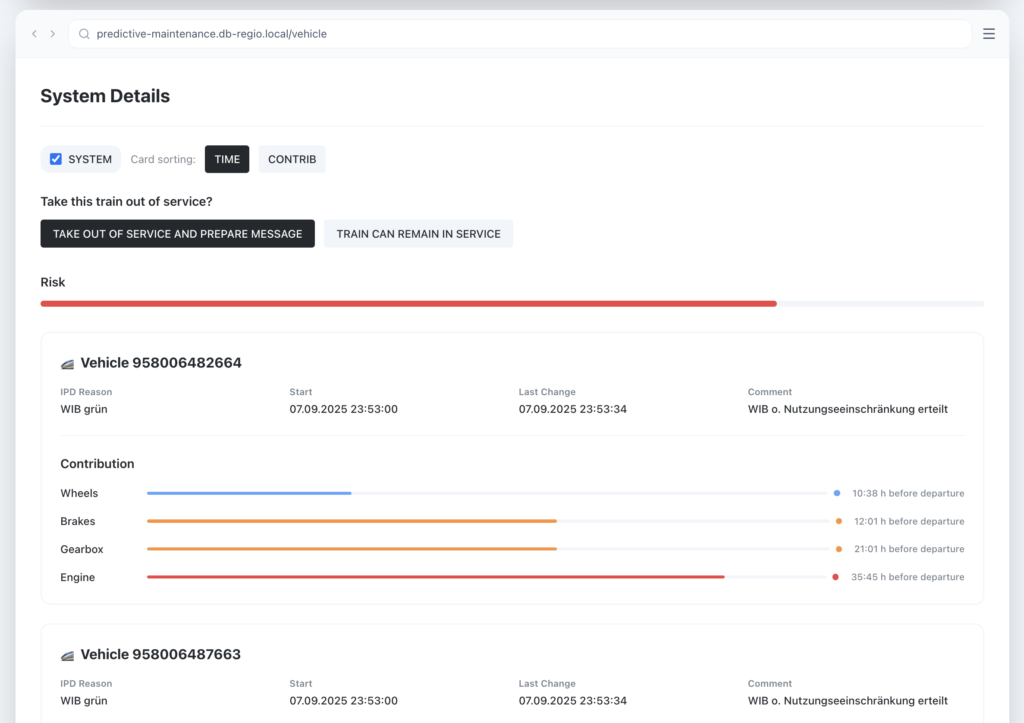
DB Regio became the first rail operator to validate a system that assigns risk scores to trains before they enter service.
Risk Scores identify at-risk trains before they enter service.
Risk Scores are not predicting punctuality. They are surfacing, based on data from maintenance logs and crew reports filed which trains are at an increased risk of failure.
The system processes all that scattered data – the fault codes, maintenance records, overnight reports – and flags at-risk trains 60 minutes before scheduled departure.
That’s the window dispatchers need. Time to trigger their action plan. Whether that is swap a train. Adjust maintenance. Make decisions before passengers board.
Risk Scores for train deployment becomes a smart decision support system for DB Regio.

Here’s What Happened with Risk Scores identifying at-risk trains
80% of at-risk trains identified at least 60 minutes before departure.
The system converted 1,600+ free-text fault codes into 57 actionable categories. Pattern recognition that was impossible manually now happens automatically.
This is highly scalable and is now running at over 18000+ fault codes. And this process took the same time to go from 1600 -> 1800 as much as it did to go from 0 -> 1600 fault codes, showing how quick the AI is at learning and adapting to new information.
Most important detail: they used data already sitting in their systems.
No waiting for sensor installation programmes. No 18-month data collection phase. The information existed – it just needed to be transformed differently.
Why This Matters to Rail Operations
Catching problems before trains enter service shifts the entire operational approach.
Instead of firefighting after failures, dispatchers can now intervene early. Before passengers are affected.
That’s how punctuality actually improves – by preventing service disruptions rather than reacting to them.
Dr. Dirk Martin, Project Lead at DB Regio, stated on the project
“The validation work with Amygda demonstrated that patterns in our operational data could predict first train risk – turning more than 250 million scattered data points into actionable insights 60 minutes before departure.
Achieving 80% detection on historical data was encouraging, and the explainability of the system means dispatchers can put the recommendations into operational context. It’s been valuable working with a team that understands the complexity of rail operations and builds AI systems that complement rather than replace human expertise.”
Amygda won Deutsche Bahn’s Innovation Award for this work. DB Regio is now expanding validation across additional S-Bahn operations.

Common Questions About Predictive Maintenance approaches in Rail
How do you predict at-risk trains before they cause disruption?
Risk scoring systems analyse existing operational data – fault codes, maintenance records, overnight reports – to identify patterns that indicate potential failures. DB Regio’s use of the system processes 250+ million data files to flag at-risk trains 60 minutes before departure.
Do you need new sensors to implement predictive maintenance?
Not necessarily. DB Regio used data already in their systems. No sensor installation programmes. No waiting months to collect new data. The information existed – it just needed proper analysis. Amygda is a full-stack maintenance AI company that works with both sensor data where it’s available, and largely untapped cmms data for predictive maintenance.
What’s the difference between reactive and predictive maintenance?
Reactive maintenance responds after problems occur. Predictive maintenance identifies at-risk equipment before failure. DB Regio shifted from reacting to train issues after departure to catching problems while trains are still in the depot.
How much advance warning do dispatchers need?
DB Regio needed 60 minutes. That’s enough time for their plan, adjust maintenance schedules, or trigger contingency plans before passengers board. Amygda’s Risk Score are shown to work accurately with upto 3 days advance warning and the same system is used for longer term forecasting 7 – 14 days ahead of developing risk in the asset fleet.
Why are first trains harder to predict than trains already in service?
First trains come from overnight maintenance with no recent operational data. Dispatchers have no visibility into what happened during the night. Unlike trains already running, there’s no continuous monitoring to spot developing issues.
Can AI replace rail maintenance experts?
No. The system complements dispatcher expertise. It synthesises scattered data and flags risks. Dispatchers use their operational knowledge to decide what action to take. It’s about giving experts better information, not replacing them.
Download the DB Regio case study on using Risk Scores to Identify At-Risk Trains
The complete case study shows:
- How the risk scoring system works
- Specific data sources they used
- Implementation approach
- Detailed performance metrics
Download the DB Regio Case Study using email function below –

